I get asked a lot of questions that involve Semantic Versioning (a.k.a. SemVer). I also get told that something some piece of software does around it is wrong. Having spent far too much time dealing versions, this post tries to clear up some of the more common misconceptions.
What Is SemVer?
Semantic Versioning, often referred to SemVer, is a specific way to deal with computer software versions. SemVer includes a specification, parser details, and regular expressions. It leaves little up for interpretation. You can read the details at https://semver.org/.
SemVer in its most basic form is illustrated in the following diagram:
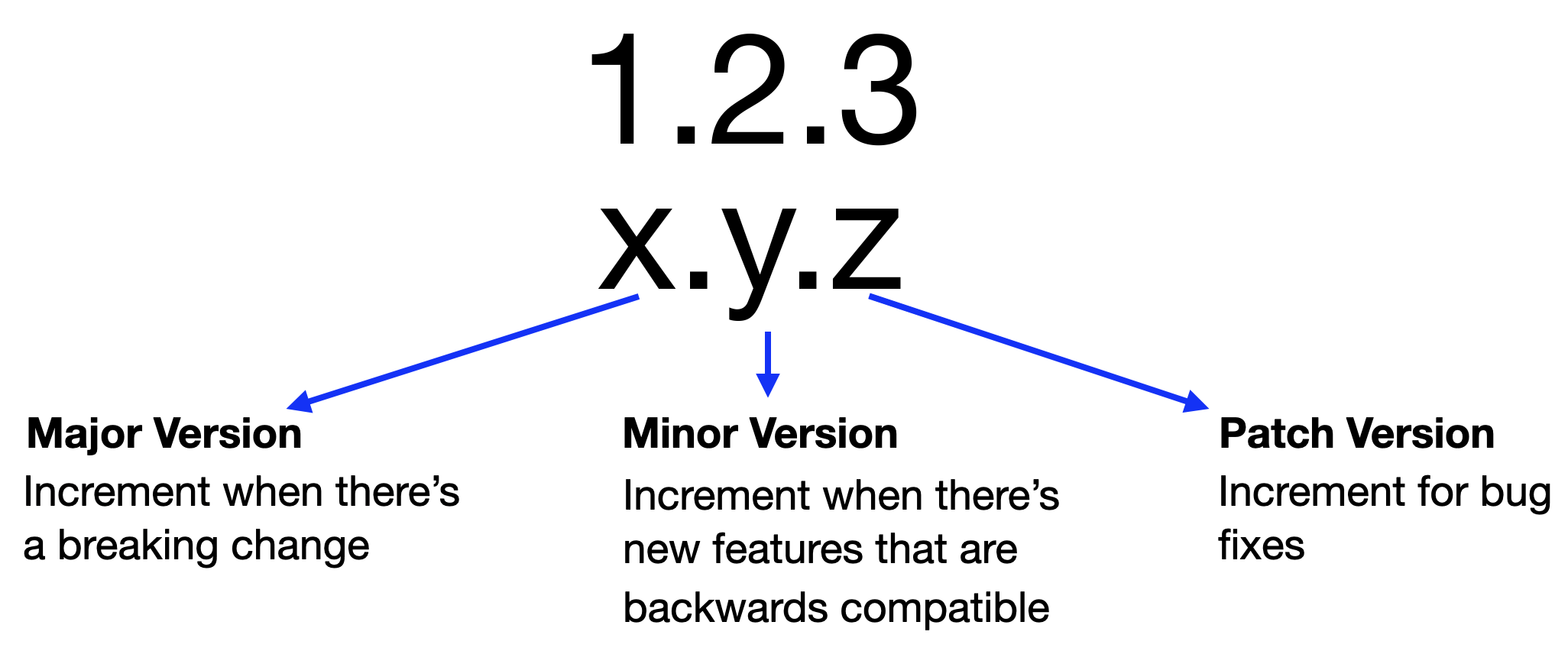
SemVer is not a general philosophy to versioning. There are specific rules in a specification meant to help avoid “dependency hell” (quoted from the spec).
Common Misconceptions
Like most specs, I don’t expect that most people have read them. They have felt the ideas out. Most of us aren’t excited about reading software specs. They aren’t “page turners”. So, I’m not surprised when misconceptions pop up. These just happen to be some of the more common ones I encounter.
Range Comparisons Are Not Part Of The Spec
It’s common to specify a range, like >=1.2.3, and then check one of more versions against it. Most tools and libraries provide an easy way to do this. Helper characters exist to shorten range syntaxes. You might have seen ~, ^, and *. Nothing to do with ranges is in any specification. The specification does tell us about ordering when there is a set of versions. But, range syntaxes and handling aren’t specified and you can find differences between tools.
For the development I do, I look at what other tools have implemented and try to keep the same syntax or do something similar. This isn’t always possible as other popular tools may not be doing the same things. But, in general things are the same or close to it.
Pre-release Versions and Compatibility
Pre-release versions are those versions that have a - and then something after at. For example, 1.2.3-dev.1. The specification specifically calls them “pre-release” versions and states:
Pre-release versions have a lower precedence than the associated normal version. A pre-release version indicates that the version is unstable and might not satisfy the intended compatibility requirements as denoted by its associated normal version.
There are two important things here.
- These pre-release versions come before the release versions. So
1.2.3 > 1.2.3-dev.1. - The normal compatibility may not be satisfied. It’s not a stable release so there may be compatibility problems.
Tooling has adopted the notion that you need to opt-in to looking at pre-releases. For example, the semver library most widely used in nodejs (and by npm itself) requires opt-in to see pre-releases.
There is good reason for this opt-in and one I learned early in my development of semver tooling. If you include everything when dealing with ranges, pre-releases are going to inevitably get into production by accident. Opting in stops this from happening.
ASCII Is Alive And Well In SemVer
So much of what we write is handled as something capable of holding many characters, like UTF-8. But, SemVer is based on ASCII and that has some interesting consequences. For example, 1.2.3-alpha.1 > 1.2.3-Beta.2. Just reading that, you would think that Beta is higher than alpha. But, it all comes down to case.
In ASCII, the uppercase letters have a lower precedence than the lowercase letters as a group. So, first you have numbers, then you have uppercase letters, then you have lowercase letters. The lowercase a in alpha comes after the capital B in Beta.
If you like visuals, a site with a table can be useful. Here’s one example: https://www.ascii-code.com/
Placement Of Numbers In Pre-releases Matter
Do you see a functional difference between 1.2.3-dev10 and 1.2.3-dev.10? There is a major difference.
The specification says two important things:
a series of dot separated identifiers immediately following the patch version
and
Numeric identifiers MUST NOT include leading zeroes.
SemVer pre-releases are designed to be broken up into groups that are separated by a .. This is really useful.
Consider how comparisons work in ASCII strings and numbers. Here are two examples:
1.2.3-dev10 < 1.2.3-dev91.2.3-dev.10 > 1.2.3-dev.9
In the first case, the pre-release is string comparisons under ASCII. The 9 comes after the 1 so it’s greater. String comparisons are missing the context.
In the second case the numbers are broken out by a . separator and can be easily seen as numbers. So, a number comparison can easily be used and the ordering will make more sense.
Build Metadata Is Just Metadata
The + sign can be use add build metadata to the version. Sometimes people want to use that for ordering. The spec states:
Build metadata MUST be ignored when determining version precedence. Thus two versions that differ only in the build metadata, have the same precedence.
Build metadata really is just metadata.
Leaning In
Software versioning isn’t usually a hill to die on. It’s often much easier to go with the system in front of you and SemVer is widely adopted. Using the quirks to your advantage can make your work easier.