When we (really Dr. Butcher) crafted the Swift to WebDAV proxy, the architecture mattered. The first two attempts at building the proxy raised issues technology and architecture issues that needed to be worked out. For example, our second attempt worked well as long as the files weren’t large. But as object storage users know, there are times you want to work with large files.
What follows is what we learned architecturally creating the proxy.
Authentication
WebDAV needs to authenticate with a username and password for this to work. The alternative form of authentication, digest authentication, requires access to an MD5 version of the password which we don’t have.
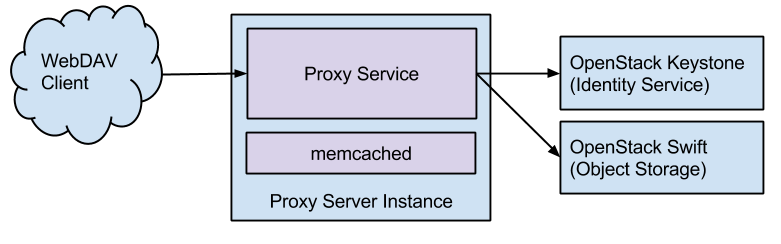
When the WebDAV client tries to authenticate against the WebDAV endpoint it will pass in a username and password. For the proxy to communicate with Swift it will need a token. To avoid communicating with Keystone for each request, the token and some other information is stored in memcached.
If the token expires or becomes invalid the proxy service will ask the WebDAV client to re-authenticate.
Projects (Tenants)
WebDAV is able to provide a username and password. OpenStack scopes assets to projects, formerly called tenants. To handle passing all 3 pieces of information to Swift the project Id is collected in the URL. For example,
https://webdav-endpoint.region.example.com/1234/
Individual proxy instances are configured to work with a specific region. A proxy setup will be needed for each supported region. This allows the setup to scale from a single region to numerous geo-located ones without issue.
Passing Data
The proxy service is a translating proxy. For example, when the WebDAV client requests a list of the contents within a directory the proxy service translates that to the correct Swift call. The response from Swift is converted into the appropriate format for the WebDAV client.
When data is passed, specifically files, the proxy service passes the content through the proxy to the other side. That means that fetching a file, even a large file, happens almost immediate. Files are not stored on the proxy so it doesn’t need to have a large cache. Instead they simply pass through changing formats as needed.
In Practice
This setup has let me transfer large files, in the gigabyte range, without issue. I’ve been able to use it on Mac, Linux, Windows, tablets, and even my phone.